SQL에는 집합 개념을 이용한 Union(합집합), Intersect(교집합), Except(차집합) 연산자가 존재한다.
먼저 union 연산자 부터 살펴보자.
Union 연산자는 연결된 select문의 결과 값을 합집합으로 묶어준다.
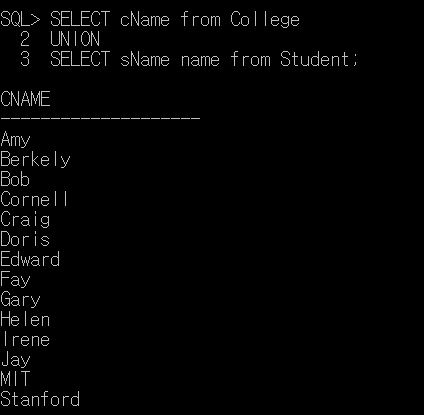
조회된 데이터에 대해서 기본적으로 중복을 허용하는 Relation Algebra나 SELECT문과는 달리 SET operator에서는 데이터의 중복을 허용하지 않기 때문에, Union 연산의 결과 값은 중복이 제거되어 있다. 아래 사진을 보자.

실제로 조회된 결과를 보면 college의 이름과 student의 이름이 같이 존재하는 것을 확인할 수 있다.
이때 출력된 데이터의 column이름을 확인하면 Cname으로 되어있는 것을 볼 수 있다.
즉 union연산에서는 먼저 실행된 select 문으로 나중에 실행된 select의 문의 결과가 포함된다.

좀 더 살펴보면 Cname과 Sname의 데이터 전체 개수는 16개이지만, Union의 결과로 출력된 데이터들은 14개 인것을 볼 수 있다. 이를 통해 Student테이블의 SNAME컬럼에서 Craig, Amy 데이터가 자동으로 중복 제거 되어 있다는 것을 확인할 수 있다.
이때 만약 중복되어 있는 값까지 모두 조회하고 싶다면 Union All 연산자를 사용하면 된다. 아래 사진을 확인해보자.
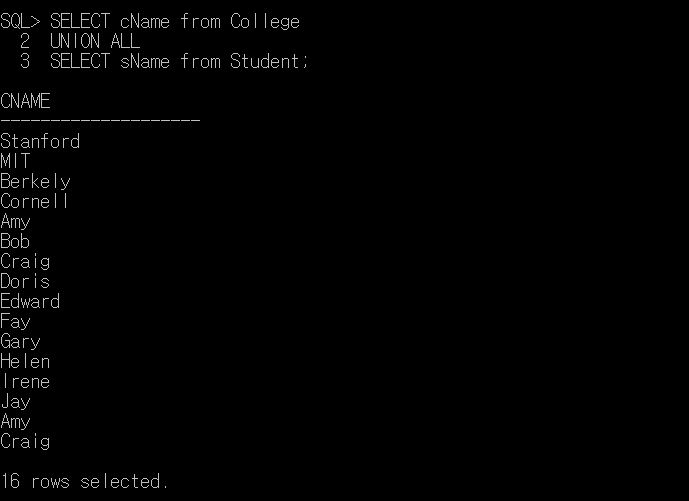
Union all 연산자를 사용했더니 Amy와 Craig 데이터가 두번씩 등장한 것을 볼 수 있으며, 출력된 데이터도 16개로 늘어있는 것을 확인할 수 있다.
Union 연산과 Union All 연산에도 alias를 사용할 수 있다.

물론 먼저 시행되는 SELECT문에 사용된 alias가 적용되는 것을 위 사진을 통해 확인할 수 있다.
다음으로 intersect 연산을 살펴보자.
Intersect 연산자는 먼저 작성한 SELECT문의 결과와 다음으로 실행되는 SELECT문의 결과 값을 교집합으로 처리한다.
즉, 두 SELECT문에서 중복되는 데이터만을 출력해준다. 아래 사진을 확인해보자.

Apply 테이블에서 지원한 학과가 CS인 학생들의 ID 데이터는 총 7개이고, 지원한 학과가 EE인 학생들은 총 3명이다.
intersect 연산을 통해서 두 학과 모두에 지원한 학생들의 데이터만 추려내면, 123,123,345 데이터만이 남게되는데, SET operator는 기본적으로 중복을 허용하지 않기 때문에 중복된 데이터까지 없애주고 나면 123, 345로 총 두개의 데이터만 출력된다.
마지막으로 Except연산자를 살펴보자.
(현재 예시로 사용하고 있는 DBMS는 Oracle인데, 오라클에서는 Except연산자를 Minus 연산자로써 사용하고 있다.)
Except 연산자는 먼저 작성한 SELECT문의 결과 값에서 다음으로 실행되는 SELECT문의 결과 값을 차집합 처리한다.
즉, 먼저 실행되는 쿼리문의 결과 값에서 다음으로 실행되는 쿼리문의 결과 값을 제외하고 남은 데이터만을 출력해준다.
아래 사진을 살펴보자.


지원한 학과가 CS인 학생들 중에서 EE학과에 지원한 학생들의 데이터를 삭제해주고, 중복까지 없애서, 총 543, 876, 987 3개의 데이터만이 조회된 것을 확인할 수 있다.
'DataBase' 카테고리의 다른 글
| SQL - natural join, cross join, self join (0) | 2019.09.21 |
|---|---|
| SQL - Equi Join(등가 조인) 과 non Equi Join(비등가 조인) (0) | 2019.09.21 |
| SQL - Alias/Order by/Like 키워드를 이용한 SELECT 문 (0) | 2019.09.16 |
| SQL - 테이블 JOIN을 이용한 SELECT문 (0) | 2019.09.16 |
| SQL - SELECT문 (0) | 2019.09.16 |



